Searching S3 Buckets (Part 1)
This is part 1 of a 2-part series on building S3 bucket search functionality. In this part, I cover a filtering approach using AWS S3's ListObjectsV2 API which works for small buckets but won't scale well to very larger ones.
In part 2, I'll explore adding a more advanced search flow using S3 Metadata and Athena to query larger buckets more efficiently.
I've been working on building a desktop S3 client this year, and recently decided to try to explore adding search functionality. What I thought could be a straightforward feature turned into a much bigger rabbit hole than I expected, with a lot of interesting technical challenges around cost management, performance optimization, and AWS API quirks.
I wanted to share my current approach in case it is helpful for anyone else working on similar problems, but also because I'm pretty sure there are still things I'm overlooking or doing wrong, so I would love any feedback.
Before jumping into the technical details, here are some quick examples of the current search functionality I'll be discussing:
Example 1: searching buckets by object key with wildcards
Example 2: Searching by content type (e.g. "find all images")
Example 3: Searching by multiple criteria (e.g. "find all videos over 1MB")
The Problem
Let's say you have 20+ S3 buckets with thousands of objects each, and you want to find all objects with "analytics" in the key. A naive approach might be:
- Call
ListObjectsV2on every bucket - Paginate through all objects (S3 doesn't support server-side filtering)
- Filter results client-side
This works for small personal accounts, but doesn't scale very well. S3's ListObjectsV2 API costs ~$0.005 per 1,000 requests at the time of writing, so multiple searches across a very large account could start to cost $$ or take a long time. Some fundamental issues:
- No server-side filtering: S3 forces you to download metadata for every object, then filter client-side
- Unknown costs upfront: You may not know how expensive a search will be until you're already running it
- Potentially slow: Querying several buckets one at a time can be very slow
- Rate limiting: Alternatively, if you hit too many buckets in parallel AWS may start throttling you
- No result caching: Run the same search twice and you pay twice
My Current Approach
The approach I describe below will not solve all of the problems above, but it does attempt to improve on several of them.
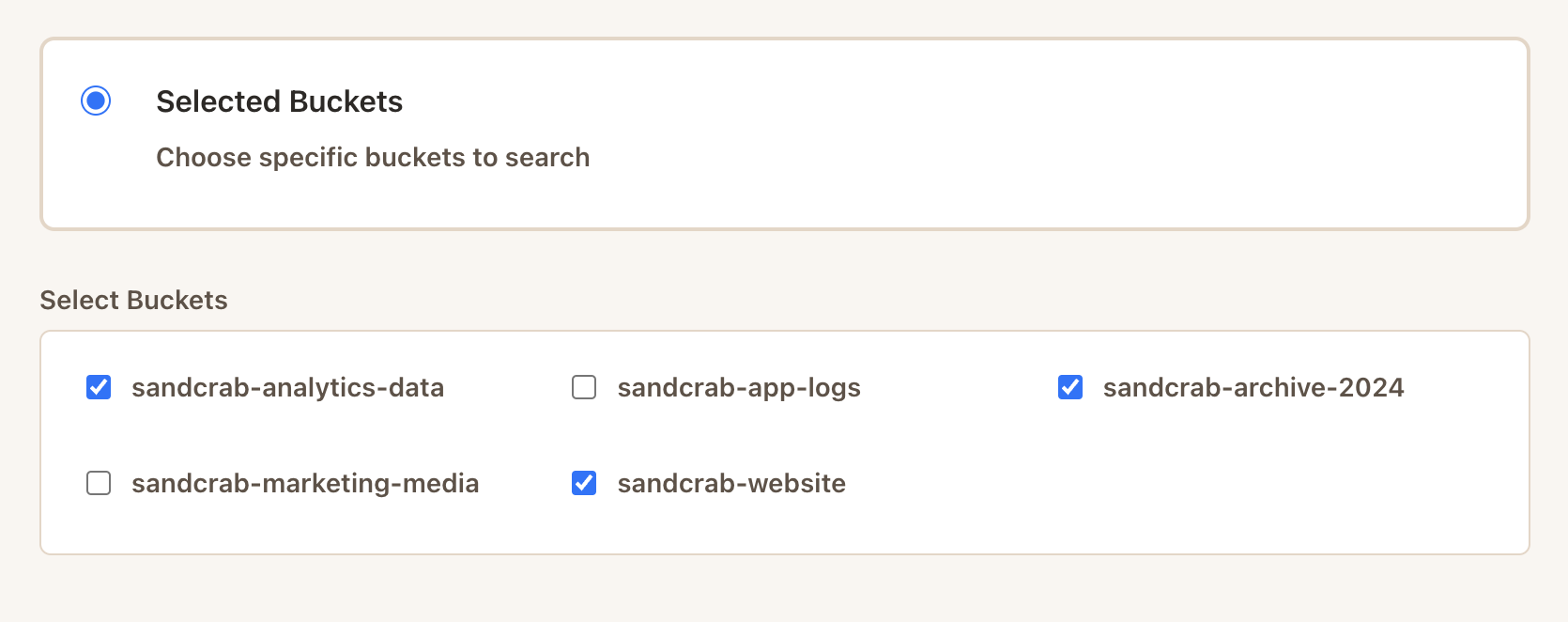
My current approach centers around a few main strategies: parallel processing for speed, cost estimation for safety, and prefix optimizations for efficiency. Users can also filter and select the specific buckets they want to search rather than hitting their entire S3 infrastructure, giving them more granular control over both scope and cost.
The search runs all bucket operations in parallel rather than sequentially, reducing overall search time. Here is a simplified example of how the frontend initiates the search and the main process orchestrates the parallel searches:
// Frontend initiates search
const result = await window.electronAPI.searchMultipleBuckets({
bucketNames: validBuckets,
searchCriteria
});
// Main process orchestrates parallel searches
const searchPromises = bucketNames.map(async (bucketName) => {
try {
const result = await searchBucket(bucketName, searchCriteria);
return {
bucket: bucketName,
results: result.results.map(obj => ({...obj, Bucket: bucketName})),
apiCalls: result.apiCallCount,
cost: result.cost,
fromCache: result.fromCache
};
} catch (error) {
return { bucket: bucketName, error: error.message };
}
});
const results = await Promise.allSettled(searchPromises);And here is a very simplified example of the core search function for each bucket:
async function searchBucket(bucketName, searchCriteria) {
const results = [];
let continuationToken = null;
let apiCallCount = 0;
const listParams = {
Bucket: bucketName,
MaxKeys: 1000
};
// Apply prefix optimization if applicable
if (looksLikeFolderSearch(searchCriteria.pattern)) {
listParams.Prefix = extractPrefix(searchCriteria.pattern);
}
do {
if (continuationToken) {
listParams.ContinuationToken = continuationToken;
} else {
delete listParams.ContinuationToken; // clear stale token
}
const response = await s3Client.send(new ListObjectsV2Command(listParams));
apiCallCount++;
// Filter client-side since S3 doesn't support server-side filtering
const matches = (response.Contents || [])
.filter(obj => matchesPattern(obj.Key, searchCriteria.pattern))
.filter(obj => matchesDateRange(obj.LastModified, searchCriteria.dateRange))
.filter(obj => matchesFileType(obj.Key, searchCriteria.fileTypes));
results.push(...matches);
continuationToken = response.NextContinuationToken;
} while (continuationToken && response.IsTruncated);
return {
results,
apiCallCount,
cost: calculateCost(apiCallCount)
};
}Instead of searching bucket A, then bucket B, then bucket C sequentially (which could take a long time), parallel processing lets us search all buckets simultaneously. This should reduce the total search time when searching multiple buckets, with some caveats.
For accounts with many buckets or large numbers of objects, firing all searches simultaneously can overwhelm S3's rate limits and trigger SlowDown throttles. In production, you'd want to add a concurrency limiter to cap the number of simultaneous bucket searches to something reasonable.
Prefix Optimization
S3's prefix optimization can reduce the search scope and costs, but it will only work for folder-like searches, not filename searches within nested directories. Currently I am trying to balance estimating when to apply this optimization for performance and cost management.
The core issue:
// Files stored like: "documents/reports/quarterly-report-2024.pdf"
// Search: "quarterly*" → S3 looks for paths starting with "quarterly" → No results!
// Search: "*quarterly*" → Scans everything, finds filename → Works, but expensive!The challenge is detecting user intent. When someone searches for "quarterly-report", do they mean:
- A folder called "quarterly-report" (use prefix optimization)
- A filename containing "quarterly-report" (scan everything)
Context-aware pattern detection:
Currently I analyze the search query and attempt to determine the intent. Here is a simplified example:
function optimizeSearchPattern(query) {
const fileExtensions = /\.(jpg|jpeg|png|pdf|doc|txt|mp4|zip|csv)$/i;
const filenameIndicators = /-|_|\d{4}/; // dashes, underscores, years
if (fileExtensions.test(query) || filenameIndicators.test(query)) {
// Looks like a filename - search everywhere
return `*${query}*`;
} else {
// Looks like a folder - use prefix optimization
return `${query}*`;
}
}Using the prefix optimization can reduce the total API calls when searching for folder-like patterns, but applying it incorrectly will make filename searches fail entirely.
Cost Management and Safeguards
The basic implementation above works, but it's dangerous. Without safeguards, users with really large accounts could accidentally trigger expensive operations. I attempt to mitigate this with three layers of protection:
- Accurate cost estimation before searching
- Safety limits during searches
- User warnings for expensive operations
Getting Accurate Bucket Sizes with CloudWatch
Cost estimations won't work well unless we can accurately estimate bucket sizes upfront. My first approach was sampling - take the first 100 objects and extrapolate. This was hilariously wrong, estimating 10,000 objects for a bucket that actually had 114.
The solution I landed on was CloudWatch metrics. S3 automatically publishes object count data to CloudWatch, giving you more accurate bucket sizes with zero S3 API calls:
async function getBucketSize(bucketName) {
const params = {
Namespace: 'AWS/S3',
MetricName: 'NumberOfObjects',
Dimensions: [
{ Name: 'BucketName', Value: bucketName },
{ Name: 'StorageType', Value: 'AllStorageTypes' }
],
StartTime: new Date(Date.now() - 24 * 60 * 60 * 1000),
EndTime: new Date(),
Period: 86400,
Statistics: ['Average']
};
try {
const result = await cloudWatchClient.send(new GetMetricStatisticsCommand(params));
if (result.Datapoints && result.Datapoints.length > 0) {
const latest = result.Datapoints
.sort((a, b) => b.Timestamp - a.Timestamp)[0];
return Math.floor(latest.Average);
}
} catch (error) {
console.log('CloudWatch unavailable, falling back to sampling');
return null;
}
}The difference is dramatic:
- With CloudWatch: "This bucket has exactly 114 objects"
- With my old sampling method: "This bucket has ~10,000 objects" (87x overestimate!)
Note: CloudWatch's NumberOfObjects metric is only updated once every 24 hours, so the counts can be stale if objects were recently added or deleted. Additionally, some AWS accounts may have storage metrics disabled, in which case this method won't work at all.
When CloudWatch isn't available (permissions, etc.), I fall back to a revised sampling approach that takes multiple samples from different parts of the keyspace. Here is a very simplified version:
async function estimateBucketSizeBySampling(bucketName) {
// Sample from beginning
const initialSample = await s3Client.send(new ListObjectsV2Command({
Bucket: bucketName, MaxKeys: 100
}));
if (!initialSample.IsTruncated) {
return initialSample.KeyCount || 0; // Small bucket, we got everything
}
// Sample from middle of keyspace - note this is arbitrary and imperfect
const middleSample = await s3Client.send(new ListObjectsV2Command({
Bucket: bucketName, MaxKeys: 20, StartAfter: 'm'
}));
// Use both samples to estimate more accurately
const middleCount = middleSample.KeyCount || 0;
if (middleCount === 0) {
return Math.min(500, initialSample.KeyCount + 100); // Likely small
} else if (middleSample.IsTruncated) {
return Math.max(5000, initialSample.KeyCount * 50); // Definitely large
} else {
const totalSample = initialSample.KeyCount + middleCount;
return Math.min(5000, totalSample * 5); // Medium-sized
}
}Note: The StartAfter: 'm' approach assumes keys are evenly distributed alphabetically, which may not be true. For example, if most of your keys start with "log-" or "data-", sampling at "m" will miss the bulk of your objects and badly underestimate. A better approach might be to randomize starting points or sample multiple letters/numbers to get a more balanced estimate.
Circuit Breakers for Large Buckets
With more accurate bucket sizes, I can now add in automatic detection for buckets that could cause expensive searches:
const LARGE_BUCKET_THRESHOLD = 500000; // 500k objects
if (bucketSize > LARGE_THRESHOLD) {
return {
error: 'LARGE_BUCKETS_DETECTED',
largeBuckets: [{ name: bucketName, objectCount: bucketSize }],
options: [
'Cancel Search',
'Proceed with Search'
]
};
}When triggered, users get clear options rather than accidentally triggering a $$ search operation.
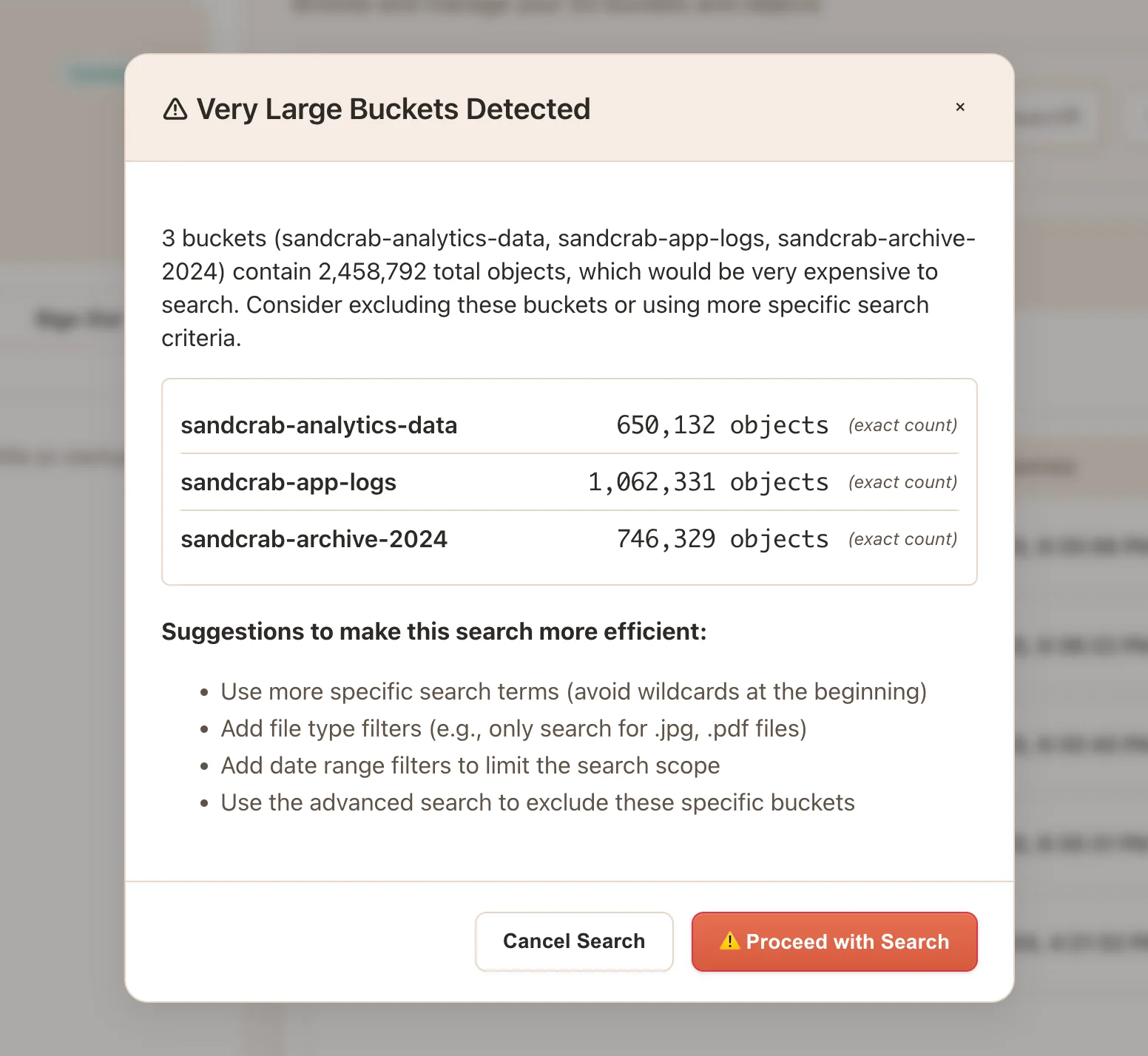
The example 500k threshold is somewhat arbitrary, ideally this could be configurable for the user's requirements, cost tolerance, etc.
Pre-Search Cost Estimation
With accurate bucket sizes, I can also better estimate costs upfront. Here is a very simplified example of estimating the search cost:
async function estimateSearchCost(buckets, searchCriteria) {
let totalCalls = 0;
const bucketEstimates = [];
for (const bucketName of buckets) {
const bucketSize = await getExactBucketSize(bucketName) ||
await estimateBucketSizeBySampling(bucketName);
let bucketCalls = Math.ceil(bucketSize / 1000); // 1000 objects per API call
// Apply prefix optimization estimate if applicable
if (canUsePrefix(searchCriteria.pattern)) {
bucketCalls = Math.ceil(bucketCalls * 0.25);
}
totalCalls += bucketCalls;
bucketEstimates.push({ bucket: bucketName, calls: bucketCalls, size: bucketSize });
}
const estimatedCost = (totalCalls / 1000) * 0.005; // S3 ListObjects pricing
return { calls: totalCalls, cost: estimatedCost, bucketBreakdown: bucketEstimates };
}Now, if we detect a potentially expensive search, we can show the user a warning with suggestions and options instead of getting surprised by costs
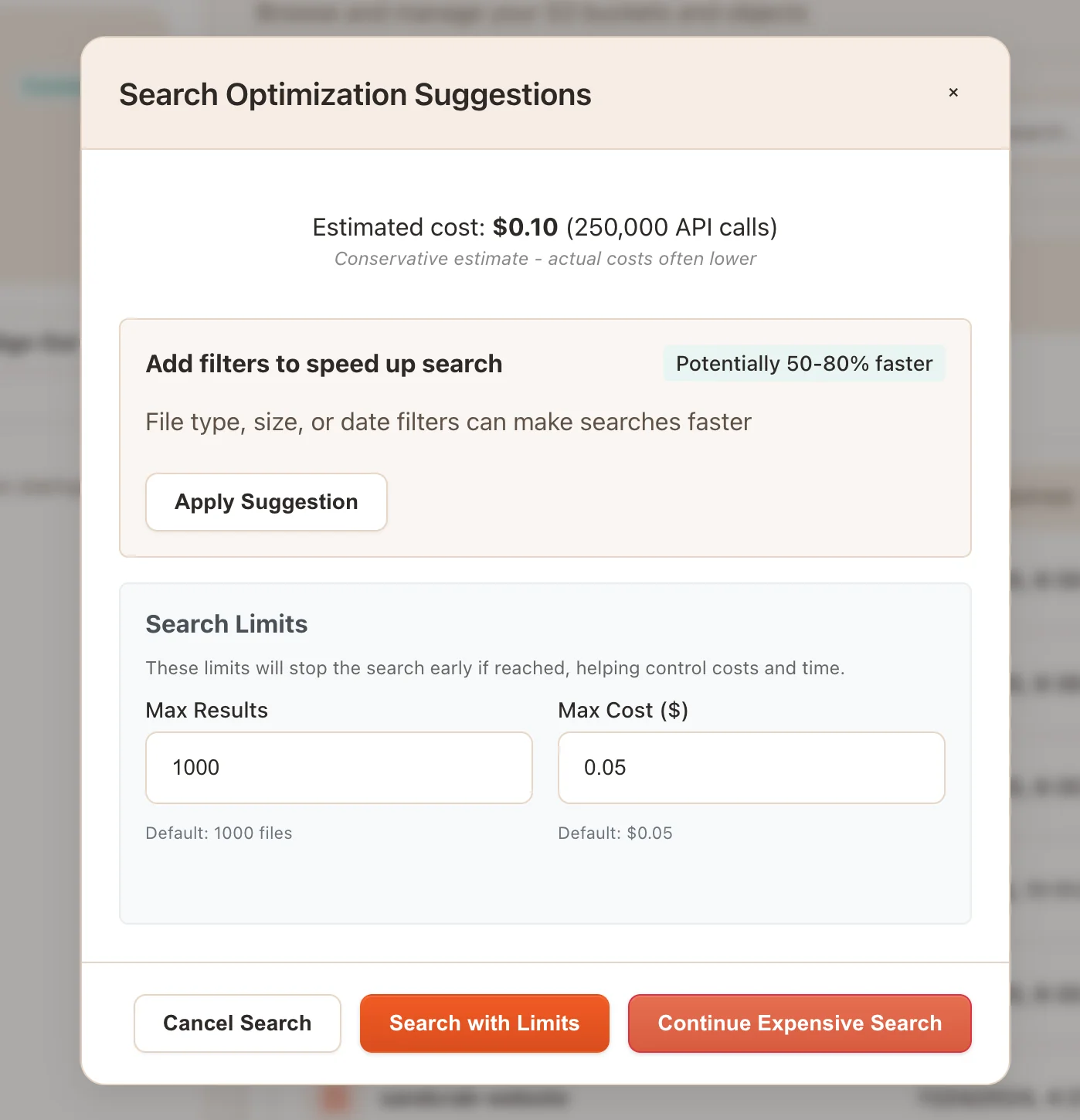
Runtime Safety Limits
Beyond the upfront bucket size checks and cost estimation, I've added several runtime safety mechanisms to prevent runaway searches on massive buckets. These limits are enforced during the actual search:
async function searchBucket(bucketName, searchCriteria, progressCallback) {
const results = [];
let continuationToken = null;
let apiCallCount = 0;
const startTime = Date.now();
// ... setup code ...
do {
// Safety checks before each API call
if (results.length >= maxResults) {
console.log(`Stopped search: hit result limit (${maxResults})`);
break;
}
if (calculateCost(apiCallCount) >= maxCost) {
console.log(`Stopped search: hit cost limit ($${maxCost})`);
break;
}
if (Date.now() - startTime >= timeLimit) {
console.log(`Stopped search: hit time limit (${timeLimit}ms)`);
break;
}
// Make the API call
const response = await s3Client.send(new ListObjectsV2Command(listParams));
apiCallCount++;
// ... filtering and processing ...
} while (continuationToken);
return { results, apiCallCount, cost: calculateCost(apiCallCount) };
}These safety limits apply to both the global search and per-bucket to trigger an early exit. When any limit is hit, we show the user a detailed warning explaining what happened and why the search was stopped.
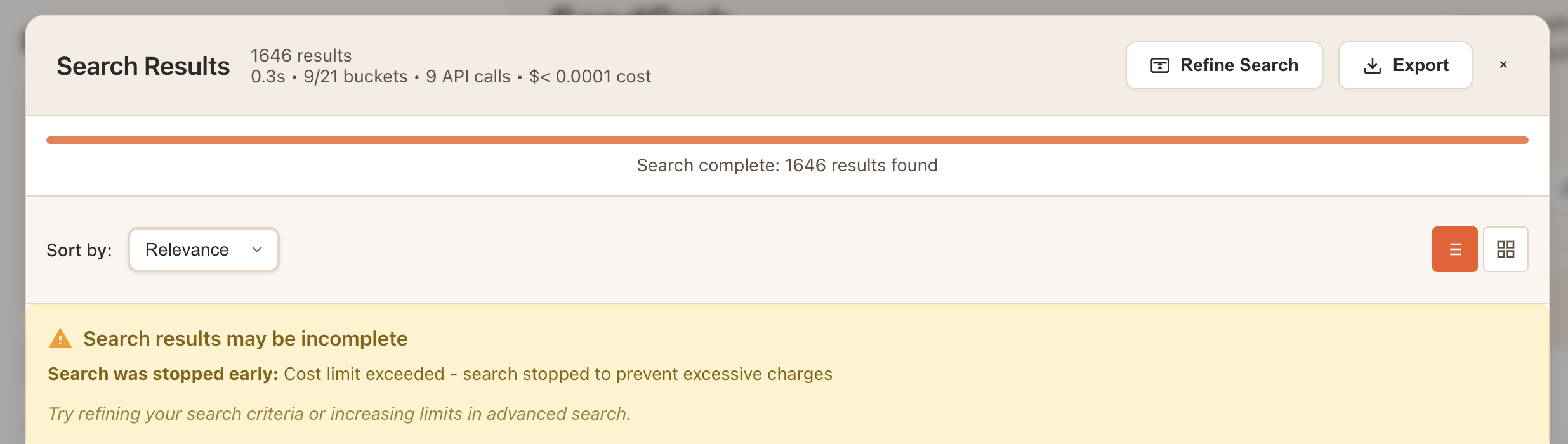
Caching Strategy
Nobody wants to wait for (or pay for) the same search twice. To address this I also implemented a cache:
function getCacheKey(bucketName, searchCriteria) {
return `${bucketName}:${JSON.stringify(searchCriteria)}`;
}
function getCachedResults(cacheKey) {
const cached = searchCache.get(cacheKey);
return cached ? cached.results : null;
}
function setCachedResults(cacheKey, results) {
searchCache.set(cacheKey, {
results,
timestamp: Date.now()
});
}Note: Using JSON.stringify(searchCriteria) for cache keys can create cache misses if object property order changes. In production, you'd want to normalize the search criteria object to ensure consistent key generation.
Now in the main bucket search logic, we check for cached results and return them immediately if found:
async function searchBucket(bucketName, searchCriteria, progressCallback) {
try {
const cacheKey = getCacheKey(bucketName, searchCriteria);
const cachedResults = getCachedResults(cacheKey);
if (cachedResults) {
log.info('Returning cached search results for:', bucketName);
return { success: true, results: cachedResults, fromCache: true, actualApiCalls: 0, actualCost: 0 };
}
// ... rest of logic ...
}
}Pattern Matching Implementation
S3 doesn't support server-side filtering, so all filtering happens client-side. I attempt to support several pattern types:
function matchesPattern(objectKey, pattern, isRegex = false) {
if (!pattern || pattern === '*') return true;
if (isRegex) {
try {
// Note: In production, user-provided regex should be sanitized
const regex = new RegExp(pattern, 'i');
const fileName = objectKey.split('/').pop();
return regex.test(objectKey) || regex.test(fileName);
} catch (error) {
return false;
}
}
// Use minimatch for glob patterns
const fullPathMatch = minimatch(objectKey, pattern, { nocase: true });
const fileName = objectKey.split('/').pop();
const fileNameMatch = minimatch(fileName, pattern, { nocase: true });
// Enhanced support for complex multi-wildcard patterns
if (!fullPathMatch && !fileNameMatch && pattern.includes('*')) {
const searchTerms = pattern.split('*').filter(term => term.length > 0);
if (searchTerms.length > 1) {
// Check if all terms appear in order in the object key
const lowerKey = objectKey.toLowerCase();
let lastIndex = -1;
const allTermsInOrder = searchTerms.every(term => {
const index = lowerKey.indexOf(term.toLowerCase(), lastIndex + 1);
if (index > lastIndex) {
lastIndex = index;
return true;
}
return false;
});
if (allTermsInOrder) return true;
}
}
return fullPathMatch || fileNameMatch;
}We check both the full object path and just the filename to make searches intuitive. Users can search for *documents*2024* and find files like "documents/quarterly-report-2024-final.pdf".
// Simple patterns
"*.pdf" → "documents/report.pdf" ✅
"report*" → "report-2024.xlsx" ✅
// Multi-wildcard patterns
"*2025*analytics*" → "data/2025-reports/marketing-analytics-final.xlsx" ✅
"*backup*january*" → "logs/backup-system/january-2024/audit.log" ✅
// Order matters
"*new*old*" → "old-backup-new.txt" ❌ (terms out of order)Real-Time Progress Updates
Cross-bucket searches can take a while, so I show real-time progress:
if (progressCallback) {
progressCallback({
bucket: bucketName,
objectsScanned: totalFetched,
resultsFound: allObjects.length,
hasMore: !!continuationToken,
apiCalls: apiCallCount,
currentCost: currentCost,
timeElapsed: Date.now() - startTime
});
}The UI updates in real-time showing which bucket is being searched and running totals.
Advanced Filtering
Users can filter by multiple criteria simultaneously:
// Apply client-side filtering
const filteredObjects = objects.filter(obj => {
// Skip directory markers
if (obj.Key.endsWith('/')) return false;
// Apply pattern matching
if (searchCriteria.pattern &&
!matchesPattern(obj.Key, searchCriteria.pattern, searchCriteria.isRegex)) {
return false;
}
// Apply date range filter
if (!matchesDateRange(obj.LastModified, searchCriteria.dateRange)) {
return false;
}
// Apply size range filter
if (!matchesSizeRange(obj.Size, searchCriteria.sizeRange)) {
return false;
}
// Apply file type filter
if (!matchesFileType(obj.Key, searchCriteria.fileTypes)) {
return false;
}
return true;
});This lets users do things like "find all images larger than 1MB modified in the last week" across multiple S3 buckets.
What I'm Still Working On
- Cost prediction accuracy - When CloudWatch permissions are not available, my estimates are still quite limited
- Flexible Limits - For now, the search limits are conservative and hardcoded. In the future, ideally more of these limits (large bucket size flag, max cost per search, etc) could be configurable in the app settings by the user
Alternatives and Scalability
The approach outlined here works well for smaller to medium S3 accounts, but it hits a scalability wall due to the limitations of the ListObjectsV2 API. No matter how much we optimize the client-side filtering and caching, we're still forced to download and scan metadata for every object. For larger S3 bucket searching, we need a different architectural approach entirely.
In part 2 of this series, I'll explore implementing an S3 Metadata + Athena approach to enable querying across larger buckets without the cost and performance limitations of the ListObjectsV2 API.